Click for more details below
Tokenization/Parsing
Remove stopwords, lemmatization, stemming
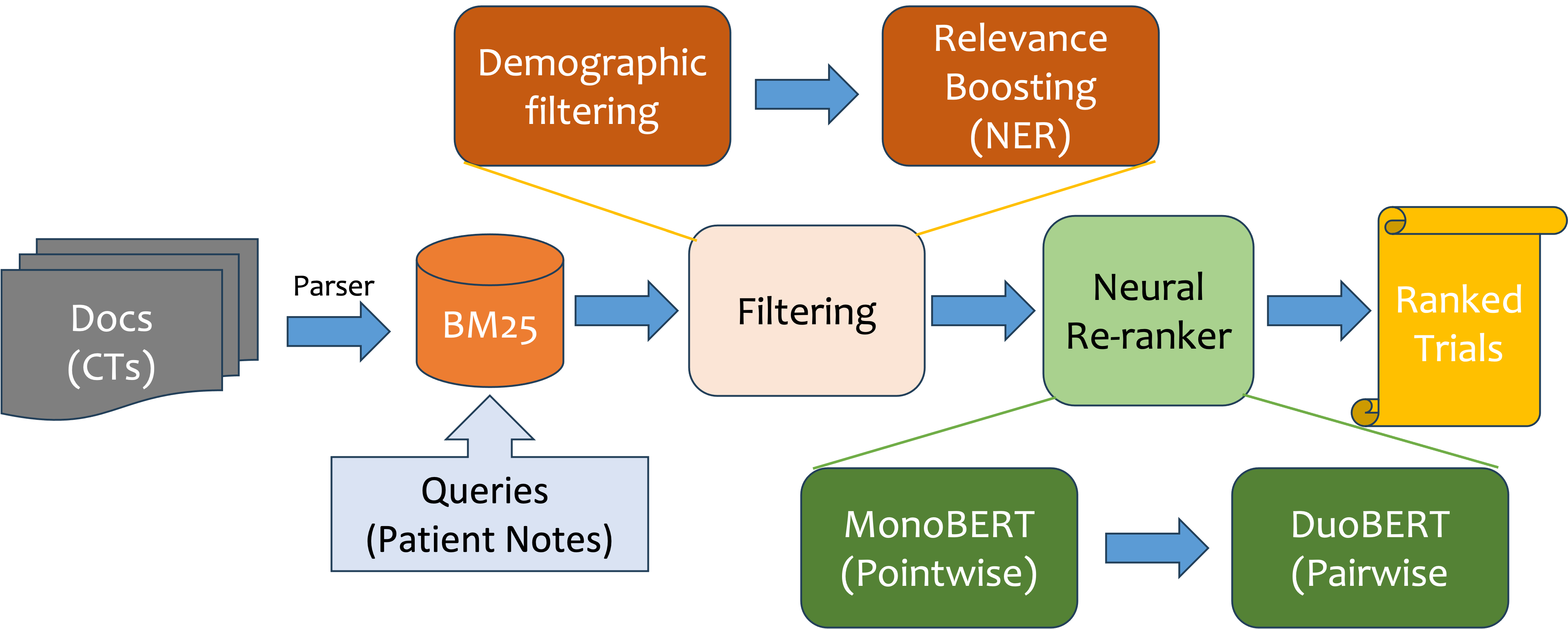
Search System and techniques
BM25, Demographic Filtering. Relevance Boosting with Medical NER
Re-ranking System
MonoBERT, DuoBERT
Adhoc Query Generation with T5 model
SIGIR query pairs for training, result boosting
Tokenization/Parsing
Depending on the specific structure of the documents, we perform data preprocessing steps including removing stopwords, lemmatization, and stemming.
Search System
- BM25
- Demographic Filtering (DF)
- Relevance Boosting with Medical NER
Introduced by Robertson and Jones , BM25 is a widely used ranking function calculating the relevance of a document to a query. Meanwhile, BM25 also considers the frequency and distribution of query terms in the document.
DF uses users' demographic data for ranking in the recommendation system. In our project, we apply it by extracting the minimum age, maximum age and gender from documents while extracting age, gender of the patient with Named Entity Recognition (NER). In addition, trials that does not match patient demographics are moved to the bottom of the initial ranking list/penalized by a factor.
Keywords and condition section of clinical trials are extracted. We use biomedical NER to retrieve Biological_structure, Disease_disorder, Sign_symptom, History entities from doc. In addition, trials that match patient medical entities are boosted based on the number of matches.
Re-ranking System
- MonoBERT
- DuoBERT
We applied two BERT-based models -- MonoBERT and DuoBERT -- introduced by Nogueria et al. in 2019 . MonoBERT and DuoBERT formulate the ranking problem as pointwise and pairwise classification respectively with more details below.
MonoBERT is a BERT encoder with a single neuron output layer connected to the encoder's pooled layer with dropout. In addition to the pointwise approach, the re-rankers are also trained using a cross-entropy loss.
Target labels are derived from corresponding relevance judgements of the training datasets. For SIGIR - revelance lables 0 constitutes negative exmaples while 1 and 2 constitute positive examples. For TREC - relevance labels 0 and 1 constitute 0 and 1 constitute negative examples and label 2 constitutes positive examples.
We re-rank the top 100 documents according to the predicted raw score.
DuoBERT adopted a pairwise approach that compares pairs of documents. To illustrate, the re-reanker estimates the probability one candidate is more relevant to the other, denoted by P(di >dj | q, di, dj) where di >dj meaning di is more relevant than dj.
We use a pretrained sentence transformer trained on SNLI, MNLI, MEDNLI and SCINLI to generate embeddings.
Cosine similarity between query and 2 documents are calculated and negated.
Adhoc Query Generation with T5 model
A Text-to-Text Transfer Transformer (T5)-base model is finetuned for query generation. We trained the model on SIGIR (description, ad-hoc) query pairs.
We found that the results often contain excerpts from the description. In addition, we boosted the results for TREC but Synthetic queries performs worse for SIGIR.