Experimental results
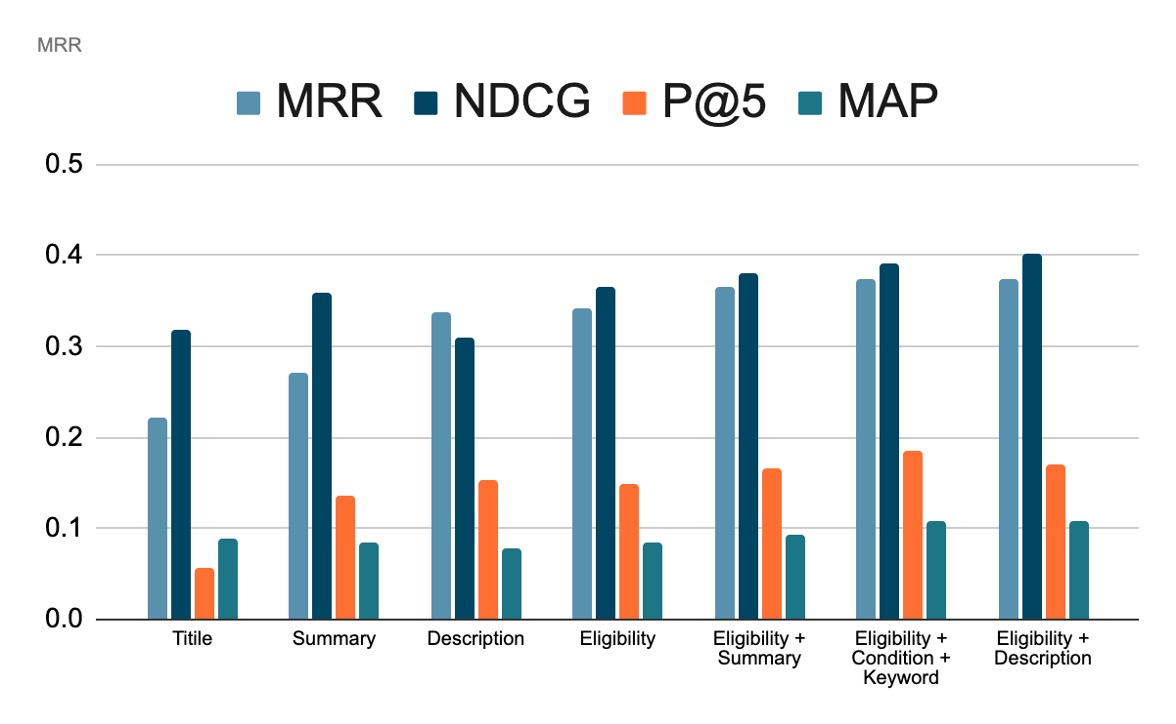
Different Sections of CTRs (SIGIR dataset)
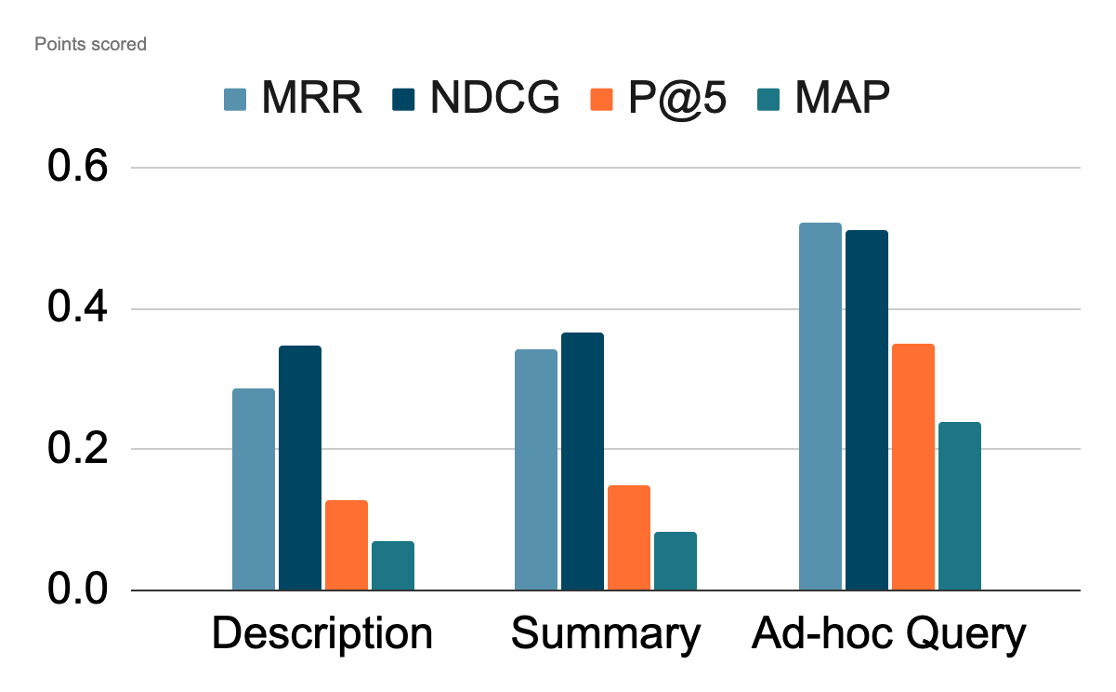
Different Types of Topics (SIGIR dataset)
| System | MRR | NDCG | P5 | MAP |
|---|---|---|---|---|
| BM25 | 0.7289 | 0.4909 | 0.5519 | 0.1720 |
| BM25+ Demographic Filtering |
0.7387 | 0.4953 | 0.5600 | 0.1752 |
| BM25+ Relevance Boosting |
0.7495 | 0.4953 | 0.5439 | 0.1776 |
| BM25+ Demographic Filtering + Relevance Boosting | 0.7378 | 0.5004 | 0.5466 | 0.1836 |
| System | MRR | NDCG | P5 | MAP |
|---|---|---|---|---|
| BM25 (Top 100) | 0.7289 | 0.2319 | 0.5520 | 0.1162 |
| BM25+ MonoBERT(Bert) |
0.7085 | 0.2351 | 0.5307 | 0.1208 |
| BM25+ MonoBERT(SciBert) |
0.7554 | 0.2521 | 0.5687 | 0.1310 |
| BM25+ MonoBERT(BlueBert) |
0.7391 | 0.2382 | 0.5413 | 0.1220 |
| BM25 (Top 100) | 0.7289 | 0.2319 | 0.5520 | 0.1162 |
|---|---|---|---|---|
| BM25+ MonoBERT(SciBert) |
0.7554 | 0.2521 | 0.5687 | 0.1310 |
| BM25+ Sentence BERT |
0.7078 | 0.2165 | 0.5340 | 0.1011 |
| BM25+ SciBert(Mono)+ Sentence BERT(Duo) |
0.7781 | 0.2672 | 0.5453 | 0.1450 |
Conclusion
From above experimental results, we can see that our proposed models achieve relatively decent performance. However, due to the complexity of the matching clinical trials in nature, there are still many limitations and improvements open.
Future Work
For future work, in addition to improving performances via techniques in Natural Language Processing or recommendation system, one possible solution is to integrate other data structure, specifically graph in this case.
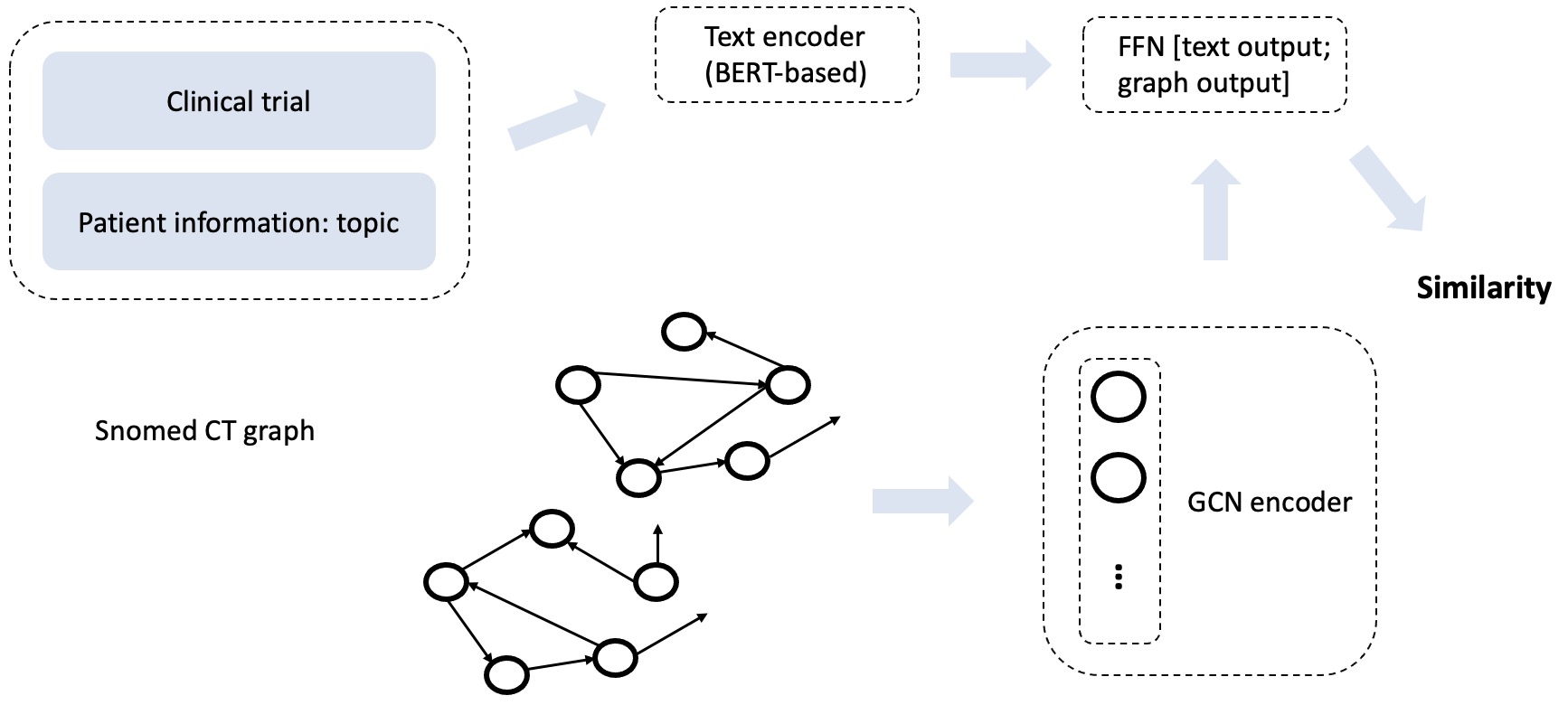
Inspired by Chang (2021) where similarity between patients are calculated and studied, we propose to apply similar idea for comparing the topic and the clinical trial:
Pairs of clinical trial and the patient information will be represented both via Snomed CT graph database and a text encoder where BERT-based ones are desired choices. After application of Graph Convolutional Network (GCN) , outputs from both encoders will be concatenated and passed the vector to a fully connected layer. A semantic similarity score can be obtained from this vector.